We're beyond excited to share the news about Llama4, Meta's latest family of open models that's about to change the game for developers and AI enthusiasts alike. At Antispace, we're always on the lookout for innovative technologies that can help our users work smarter, not harder. And Llama4 is exactly that. Llama 4 brings massive context windows, multimodal support, and modular architectures tuned for actual production use.

What's the Big Deal About Llama4?
So, what makes Llama4 so special? For starters, it's built on a Mixture-of-Experts (MoE) architecture that's like a super-efficient engine, only activating the parameters it needs to process each token. This means it's not only faster and more scalable but also more cost-effective. Plus, all Llama4 models are natively multimodal, which means they can handle both text and images seamlessly.
The Nitty-Gritty Details
If you're a tech enthusiast, you'll love the specs:
Architecture: Mixture-of-Experts (MoE) - think of it like a smart, adaptive system
Modality: Text + Image (native multimodal) - no need for external vision encoders
Adapter Support: LoRA, QLoRA, custom fine-tuning - you can tailor it to your needs
Context Capacity:1M to10M+ tokens, depending on the model - that's a lot of context!
Open-weights access: Fully open for research and integration - we're talking transparency and collaboration
Deployment: Databricks, Hugging Face, AWS, Meta Cloud - you can deploy it wherever you need
Using Llama 4 Inside Antispace
Llama 4 models are not yet integrated into the core AI pipeline in Antispace. We're evaluating how it fits into production workflows. In the meantime, devs can try them directly inside any workspace.
Type this command to test:
/llama 4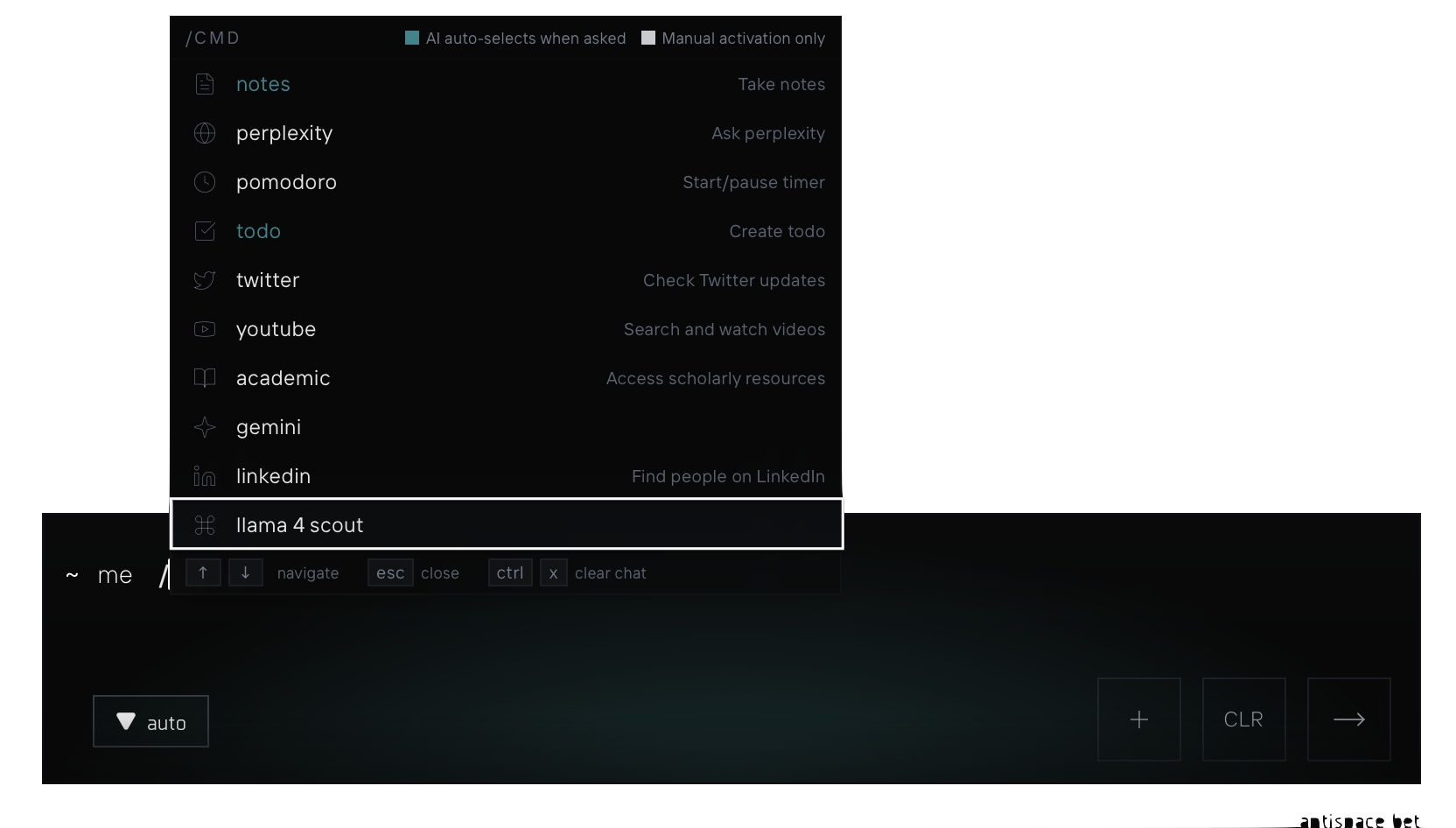
Meet the Llama4 Family
We're excited to introduce three Llama4 models, each designed for specific use cases:
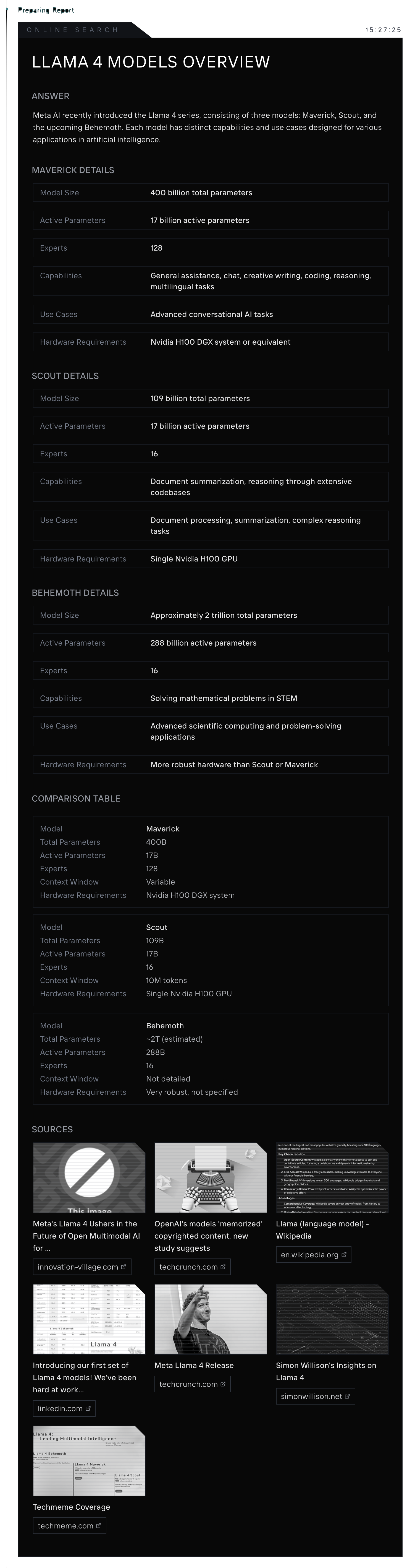
Llama 4: Maverick-X
Maverick-X is optimized for low-latency general-purpose tasks—text-first with image support.
Use it for:
Assistants and chatbots
Creative content generation
Customer service and helpdesk automation
Light image + text analysis
Specs:
Total Parameters: 420B
Active Parameters: 24B
Experts: 128
Context Window: 1M tokens
Deployment: Llama.com, AWS, Databricks
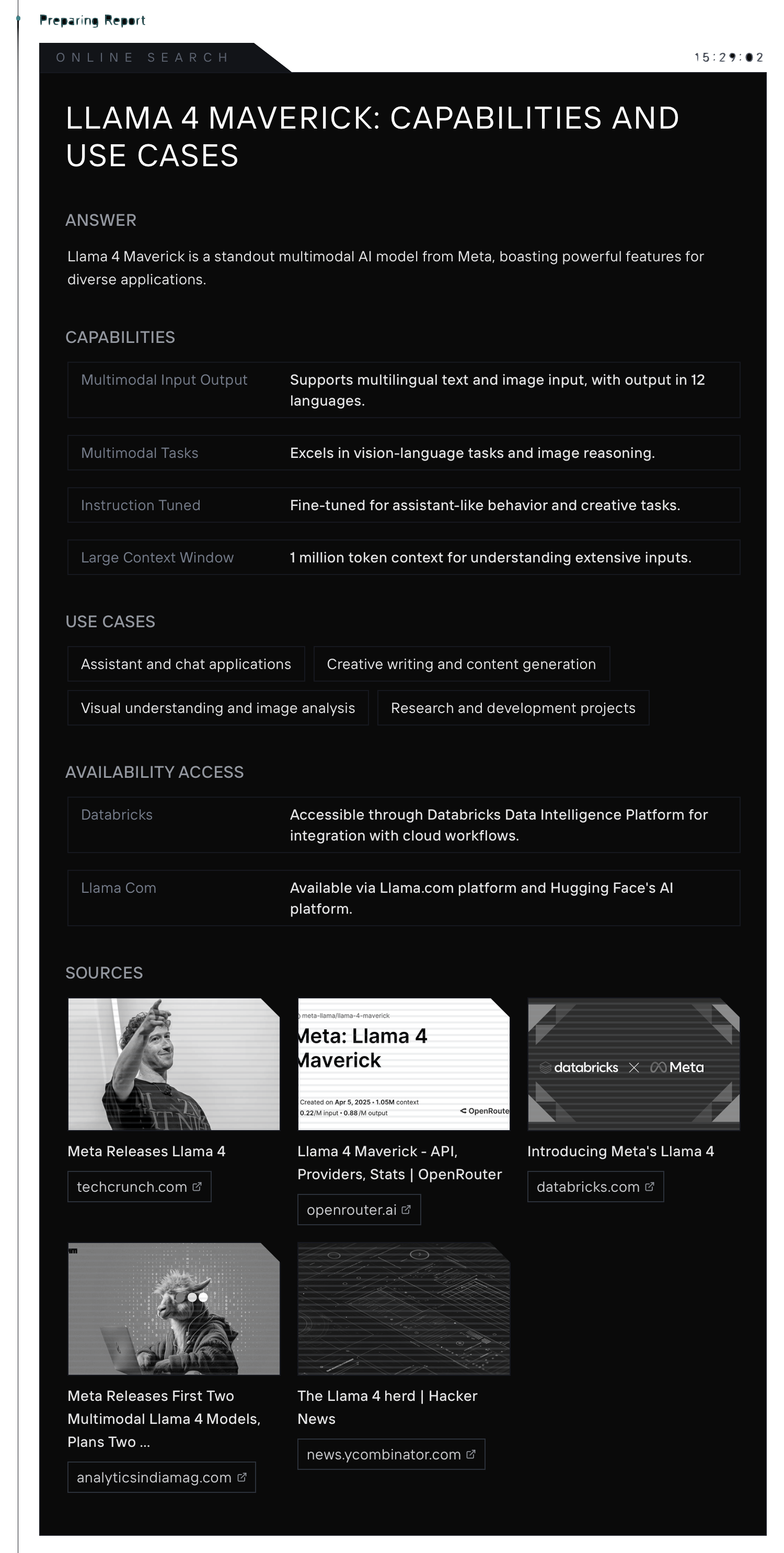
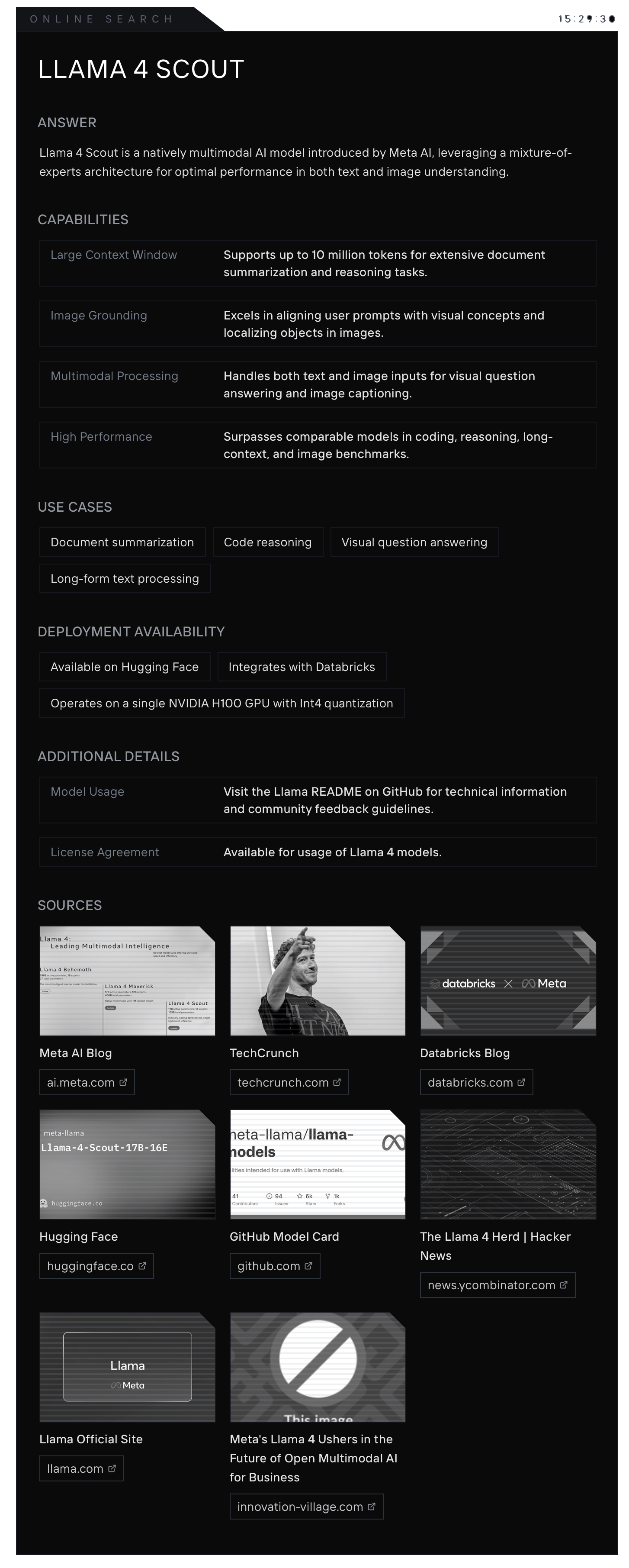
Llama 4: Scout-X [ added to Antispace ]
Scout-X is built for long-context document and code reasoning. If you need 10M tokens of context and structured output, this is it.
Use it for:
Multi-file codebase understanding
Long-document summarization
Research document QA
RAG pipelines with high token recall
Specs:
Total Parameters: 120B
Active Parameters: 24B
Experts: 32
Context Window: 10M tokens
Deployment: Hugging Face, Azure ML
Llama 4: Behemoth-X [ meta has not released yet]
Behemoth-X is the largest and most powerful in the family—aimed at large-scale scientific and STEM applications.
Use it for:
Simulation analysis
Scientific reasoning (physics, biology, etc.)
Deep math + logic workloads
Experimental agentic research
Specs:
Total Parameters: ~2.5T
Active Parameters: 320B
Experts: 64
Context Window: TBD (>10M expected)
Access: Meta Research Cloud (private beta)
The Multimodal Advantage
One of the coolest things about Llama4 is its native multimodal support. You can feed both image and text into the same prompt, without needing an external vision encoder. This opens up a world of possibilities for applications like:
Image captioning and classification
Visual grounding with text
Visual Q&A
Document layout parsing (OCR + language tasks)
The Future of AI: It's Not Just About Size
As powerful open-source models like Llama4 become more accessible, the focus shifts from model size to practical use cases. At Antispace, we're passionate about making these models work for you, silently in the background, to help you think faster, work smarter, and stay ahead.
So, what are you waiting for? Try Llama4 today and discover the possibilities! If you're curious about Llama4, type /llama in your workspace to give it a spin. We can't wait to see what you create with Llama4.